Wakacje powoli się kończą, więc tym razem będzie trochę bardziej na serio: rozwiążemy sobie chińskie zadanie o przydziale zadań w (chińskiej) fabryce. Co prawda w treści niby jest coś o Szwecji i ochotnikach, ale kto by się tam dał nabrać. Zadanie jest o tyle fajne, że na pierwszy (a nawet i na drugi) rzut oka wydaje się być na tyle bliskie rzeczywistości, że pewnie (NP-)trudne. Ale, o dziwo, nie jest!
Treść można zobaczyć tutaj. Chcemy zaplanować pracę w ciągu  kolejnych dni. Wiemy, że w
kolejnych dni. Wiemy, że w  -tym z nich potrzebnych jest przynajmniej
-tym z nich potrzebnych jest przynajmniej  pracowników. Pracownicy są podzieleni na
pracowników. Pracownicy są podzieleni na 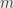 typów, pracownik -tego typu zaczyna pracę dnia
typów, pracownik -tego typu zaczyna pracę dnia  i pracuje aż do dnia
i pracuje aż do dnia  , lecz niestety musimy mu za to zapłacić
, lecz niestety musimy mu za to zapłacić 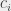 RMB. Możemy zatrudnić dowolnie wiele pracowników każdego typu, ważne jest tylko spełnienie wszystkich żądań i zminimalizowanie sumarycznego kosztu. Aha,
RMB. Możemy zatrudnić dowolnie wiele pracowników każdego typu, ważne jest tylko spełnienie wszystkich żądań i zminimalizowanie sumarycznego kosztu. Aha,  i
i  i autor wydaje się sugerować, że mogą być spore, więc rozwiązanie pewnie musi mieć raczej małą złożoność.
i autor wydaje się sugerować, że mogą być spore, więc rozwiązanie pewnie musi mieć raczej małą złożoność.
Dość często w zadaniach dotyczących szeregowania zadań, alokacji zasobów, …, dobrym pomysłem jest sformułowanie problemu jako (ważonego lub nie) przepływu w grafie. Czasami jest to bardzo łatwe (jak choćby w sytuacji, w której przydzielamy zadania pracownikom tak, żeby każdy dostał dokładnie jedno zadanie, które potrafi wykonać, i każde zadanie zostało przydzielone dokładnie jednemu pracownikowi), ale w tym przypadku chyba nie jest oczywiste. Mamy sporo parametrów i nie jest jasne, jak przetłumaczyć je wszystkie na język przepływów. Co zrobić?
Jak zwykle warto zacząć od trochę prostszej wersji. W tym przypadku dość naturalnym uproszczeniem jest założenie, że w -tym dniu chcemy dysponować dokładnie pracownikami. Tak, żeby żaden z nich nie mógł się obijać.
Taką uproszczoną wersję dość łatwo przedstawić jako najtańszy maksymalny przepływ. Wystarczy tylko popatrzeć na różnice  (dla wygody ustalmy, że
(dla wygody ustalmy, że  ). Jeśli
). Jeśli 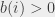 , musimy mieć
, musimy mieć  pracowników, którzy zaczynają pracę w dniu . Jeśli zaś
pracowników, którzy zaczynają pracę w dniu . Jeśli zaś 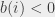 , musimy mieć
, musimy mieć 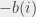 pracowników, którzy kończą wtedy pracę. Teraz można myśleć o tym tak, że w pewnym sensie chcemy sparować ze sobą żądania tych dwóch typów używając do tego pracowników. Na przykład jeśli
pracowników, którzy kończą wtedy pracę. Teraz można myśleć o tym tak, że w pewnym sensie chcemy sparować ze sobą żądania tych dwóch typów używając do tego pracowników. Na przykład jeśli  oraz
oraz  , pracownik pracujący tylko pierwszego dnia pozwala nam na zredukowanie
, pracownik pracujący tylko pierwszego dnia pozwala nam na zredukowanie  i
i 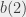 do zera. W ogólnej sytuacji cała sprawa jest trochę bardziej skomplikowana, i pewnie lepiej jest o tym myśleć w kategoriach sieci przepływowej, w której mamy jeden wierzchołek
do zera. W ogólnej sytuacji cała sprawa jest trochę bardziej skomplikowana, i pewnie lepiej jest o tym myśleć w kategoriach sieci przepływowej, w której mamy jeden wierzchołek  dla każdego dnia
dla każdego dnia  . Dla każdego typu pracownika, który zaczyna pracę w dniu , kończy , i oczekuje pensji w wysokości RMB, dorzucamy krawędź z
. Dla każdego typu pracownika, który zaczyna pracę w dniu , kończy , i oczekuje pensji w wysokości RMB, dorzucamy krawędź z  do
do  o koszcie i nieskończonej przepustowości. Dodatkowo tworzymy źródło połączone krawędzią o koszcie
o koszcie i nieskończonej przepustowości. Dodatkowo tworzymy źródło połączone krawędzią o koszcie  i przepustowości
i przepustowości  z każdym wierzchołkiem , dla którego
z każdym wierzchołkiem , dla którego 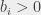 , oraz ujście połączone krawędzią o koszcie i przepustowości
, oraz ujście połączone krawędzią o koszcie i przepustowości  z każdym wierzchołkiem , dla którego
z każdym wierzchołkiem , dla którego 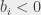 . Prosty i tendencyjny przykład z treści znajduje się na poniższej ilustracji. Każda z krawędzi jest opisana jako (koszt, przepustowość).
. Prosty i tendencyjny przykład z treści znajduje się na poniższej ilustracji. Każda z krawędzi jest opisana jako (koszt, przepustowość).

Dość oczywiste jest, że poprawnemu wyborowi pracowników odpowiada przepływ (o takim samym koszcie) wysycający wszystkie krawędzie wychodzące ze źródła (a więc także te wchodzące do ujścia, bo  ) w tak utworzonej sieci. Może trochę mniej oczywiste (ale dalej prawdziwe) jest to, że każdemu takiemu przepływowi odpowiada poprawny wybór pracowników (o takim samym koszcie!). Wynika to z faktu, że zawsze możemy wybrać tak zmodyfikować przepływ, żeby był całkowitoliczbowy, czyli przesyłał po każdej krawędzi całkowitą liczbę jednostek.
) w tak utworzonej sieci. Może trochę mniej oczywiste (ale dalej prawdziwe) jest to, że każdemu takiemu przepływowi odpowiada poprawny wybór pracowników (o takim samym koszcie!). Wynika to z faktu, że zawsze możemy wybrać tak zmodyfikować przepływ, żeby był całkowitoliczbowy, czyli przesyłał po każdej krawędzi całkowitą liczbę jednostek.
Tyle jeśli chodzi o uproszczoną wersję. Jak pozbyć się założenia, że w -tym dniu chcemy dysponować dokładnie pracownikami, a nie przynajmniej tyloma? Okazuje się to wręcz zaskakująco proste. Wystarczy tylko dodać krawędzie o koszcie i nieskończonej przepustowości z każdego  do
do  (nazwijmy je sobie krawędziami wstecznymi; nie mylić z krawędziami w tył, które są czymś zupełnie innym).
(nazwijmy je sobie krawędziami wstecznymi; nie mylić z krawędziami w tył, które są czymś zupełnie innym).
Ale właściwie niby dlaczego miałoby to działać? Pomysł jest o tyle naturalny, że po takiej modyfikacji pracownika, który wcześniej zaczynał pracę w dniu , a kończył w , teraz tak naprawdę zaczyna pracę w dniu lub później, a kończy w lub wcześniej, czyli dodanie krawędzi wstecznych pozwala nam na ewentualnie utrudnienie sobie życia, czyli jakby zwiększenie niektórych . No, pewnie nie jest to super przekonujące, spróbujmy więc podejść do kwestii w trochę bardziej systematyczny sposób.
Chcemy tak zwiększyć niektóre (lub być może wszystkie) , aby koszt przepływu wysycającego wszystkie krawędzie wychodzące ze źródła w "starej" sieci (tej bez krawędzi wstecznych) był jak najmniejszy. Warto zwrócić uwagę na to, że taki przepływ może nie istnieć! Powiedzmy, że zwiększymy o  , czyli tak naprawdę zmienimy o
, czyli tak naprawdę zmienimy o  (które może być dodatnie lub ujemne; a nawet równe zeru). Fajnie byłoby teraz pokazać, że można skonstruować przepływ o dokładnie takim samym koszcie, który wysyca wszystkie krawędzie wychodzące ze źródła w „nowej” sieci z krawędziami wstecznymi skontruoowanej dla oryginalnych .
(które może być dodatnie lub ujemne; a nawet równe zeru). Fajnie byłoby teraz pokazać, że można skonstruować przepływ o dokładnie takim samym koszcie, który wysyca wszystkie krawędzie wychodzące ze źródła w „nowej” sieci z krawędziami wstecznymi skontruoowanej dla oryginalnych .
Skorzystamy w tym celu dość oczywistej metody, mianowicie zmodyfikujemy przepływ, który już mamy. Musimy tylko jakoś poradzić sobie z tym, że zmieniliśmy przepustowości niektórych krawędzi (tych wychodzących ze źródła i tych wchodzących do ujścia). Trzeba więc przekierować te nadmiarowe jednostki. Mówiąc bardziej precyzyjnie, w każdym mamy  nadmiarowych jednostek jeśli
nadmiarowych jednostek jeśli 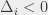 , lub brakuje nam tam
, lub brakuje nam tam  jednostek jeśli
jednostek jeśli  . Teraz zauważmy, że
. Teraz zauważmy, że 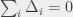 , więc może dałoby się jakoś sparować te nadmiarowe jednostki z brakującymi używając darmowych krawędzi wstecznych? Brzmi nawet spoko, należy jednak sprawdzić, że do sparowania faktycznie wystarczy takie przesyłanie wstecz.
, więc może dałoby się jakoś sparować te nadmiarowe jednostki z brakującymi używając darmowych krawędzi wstecznych? Brzmi nawet spoko, należy jednak sprawdzić, że do sparowania faktycznie wystarczy takie przesyłanie wstecz.
Popatrzmy na krawędź wstecz z do . Możemy jej użyć do sparowania nadmiarowych jednostek po prawej z brakującymi jednostkami po lewej, na pewno trzeba więc sprawdzić, że po lewej nie mamy nadmiaru. Całkowity bilans po lewej to po prostu 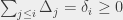 , czyli rzeczywiście jedyne co może się zdarzyć to sytuacja, w której po lewej brakuje nam pewnej liczby jednostek. Tak naprawdę oznacza to, że możemy sparować nadmiarowe jednostki z brakującymi: wystarczy tylko przesłać
, czyli rzeczywiście jedyne co może się zdarzyć to sytuacja, w której po lewej brakuje nam pewnej liczby jednostek. Tak naprawdę oznacza to, że możemy sparować nadmiarowe jednostki z brakującymi: wystarczy tylko przesłać  jednostek krawędzią wstecz łączącą z . Co pokazuje, że możemy skonstruować przepływ o dokładnie takim samym koszcie w nowej sieci.
jednostek krawędzią wstecz łączącą z . Co pokazuje, że możemy skonstruować przepływ o dokładnie takim samym koszcie w nowej sieci.
No i fajnie. Teraz trzeba by jeszcze pokazać, że mając przepływ wysycający wszystkie krawędzie wychodzące ze źródła w nowej sieci, możemy w cwany sposób zmodyfikować niektóre i skonstruować przepływ o takim samym koszcie, który wysyca wszystkie krawędzie wychodzące ze źródła w starej sieci (z nowymi ). W zasadzie działa to samo rozumowanie, którego użyliśmy przed chwilą: jeśli oznaczymy przepływ z do jako  , należy zwiększyć o . Dość łatwo w to uwierzyć wyobrażając sobie, że chcemy pozbyć się jednej jednostki płynącej Z do . W tym celu zwiększamy o jeden, wtedy także wzrasta o jeden, a
, należy zwiększyć o . Dość łatwo w to uwierzyć wyobrażając sobie, że chcemy pozbyć się jednej jednostki płynącej Z do . W tym celu zwiększamy o jeden, wtedy także wzrasta o jeden, a 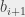 maleje (też o jeden), i zmniejszamy (o jeden) przepływ z do . Sumaryczna zmiana przeływu wchodzącego i wychodzącego do i nie ulegnie zmianie po takiej operacji.
maleje (też o jeden), i zmniejszamy (o jeden) przepływ z do . Sumaryczna zmiana przeływu wchodzącego i wychodzącego do i nie ulegnie zmianie po takiej operacji.
Czyli pokazaliśmy (choć może niezbyt formalnie), że rzeczywiście wystarczy znaleźć najtańszy przepływ, który wysyca wszystkie krawędzie wychodzące ze źródła w nowej sieci (warto zauważyć, że taki przepływ zawsze istnieje; wynika to ze sposobu konstrukcji sieci). Ale jak go znaleźć?
Pewnie można użyć napisanego wcześniej ogólnego algorytmu, który znajduje najtańszy maksymalny przepływ. Jest to na tyle znany problem, że większość z Was pewnie ma go w swojej biblioteczce. W tym konkretnym przypadku sieć przepływowa jest dość duża, konieczne jest więc skorzystanie z w miarę efektywnej implementacji. Co nawet bardziej niepokojące, dość duże mogą być , lepiej więc nie powiększać aktualnego przepływu tylko o jeden w każdym kroku. Przypomnijmy sobie, że najtańszego maksymalnego przepływu zwykle szuka się przepychając przez sieć kolejne jednostki, za każdym razem wybierając najtańszą ścieżkę w sieci residualnej. Możemy więc wybrać na takiej ścieżce krawędź o najmniejszej przepustowości (residualnej)  , a następnie przepuścić ścieżką całe jednostek na raz. Wystarcza to do rozwiązania zadania, ale nie jest zbyt podniecające jeśli chodzi o analizę czasu działania. Może dałoby się jakoś mądrzej?
, a następnie przepuścić ścieżką całe jednostek na raz. Wystarcza to do rozwiązania zadania, ale nie jest zbyt podniecające jeśli chodzi o analizę czasu działania. Może dałoby się jakoś mądrzej?
Dałoby się! Ale o tym przy innej okazji.





Tak na nietrzeźwo, to mam taki pomysł, żeby iśc od lewej do prawej i dla danego momentu t patrzeć na wszystkie oferty pracy przecinające moment t : skreślamy te oferty które są zdominowane przez inne oferty (tj. kończą się później i są tańsze, niż inne) a z tych co zostaną bierzemy najtańszą (czyli najkrótszą) a pozostałe zamieniamy na „przyrostówki”, tzn na takie pseudo oferty reprezentujące fakt, że zamiast osoby A możemy zatrudnić osobę B, co da nam dodatkowych X dni, ale musimy za to zapłacić dodatkowo Y. Te przyrostówki dorzucamy do zasobu już wcześniej zdefiniowanych ofert i jedziemy dalej, tj. rozważamy t+1.
Niestety nie mam pojęcia jaką to ma złożoność, ale impreza w Antidotum była spoko.
No niby można, choć nie widzę dwóch szczegółów: 1) raczej nie jest tak, że te pozostałe zamieniasz, raczej duplikujesz i robisz z kopii takie „przyrostówki” (no bo być może okaże się, że jakoś tam później nie możesz już wybrać osoby A, a przydałaby Ci się B), co grozi jakimś wykładniczym puchnięciem 2) w tej zamianie na „przyrostówki” trzeba uważać, żeby nie zamienić dwukrotnie tej samej osoby A, a to chyba nie jest łatwe?
Racja. Przez moment miałem nadzieję, że liczba możliwych przyrostówek jest ograniczona przez n^2 (no bo niby odpowiada zamienieniu osoby X na Y), ale to jest nie takie łatwe, bo musimy też gdzieś zakodować informację, że jak już zamienimy X na Y to np. nie możemy potem na Z, bo Z zaczyna pracę później niż t…no i robi się ów wykładniczy klops. No może nie wykładniczy bo pewnie wystarczyłaby trójka (t,X,Y) by opisać przyrostówkę, więc to jakieś n*n*m.
spoiler alert: a może program dualny rozwiązać dijkstrą?
Noo program dualny.. zawsze warto rozwiązać 🙂